
Inside Predator's kernel engine
Commercial spyware defeats Apple's pointer authentication and achieves kernel memory access. Jamf Threat Labs investigates.

By Nir Avraham (GotR00tAcce55)
Executive summary
In our previous research, we documented how Predator spyware evades iOS anti-analysis checks and defeats iOS recording indicators. Those posts revealed what Predator does — but not how it achieves the deep system access required to do it.
This post answers that question.
Through continued reverse engineering of Predator iOS samples, we build upon our first report to reveal how Predator's kernel exploitation engine powers its surveillance capabilities. The engine has never been reported on — until now.
The exploit chain analyzed in this post targets iOS versions prior to 17 and devices through the A16 generation. Apple's introduction of SPTM (Secure Page Table Monitor) in A15 devices, which moves page table management to EL2, represents a significant architectural mitigation against the kernel code modification techniques described here.
Key findings include:
- FDGuardNeonRW — A kernel read/write (R/W) primitive that uses ARM NEON vector registers as a covert data channel to read and write arbitrary kernel memory
- PAC bypass via JavaScriptCore gadget hunting — Predator searches Apple’s own JavaScriptCore framework for a specific 20-byte ARM64 instruction sequence to forge PAC-signed pointers
- A 256-entry PAC signing cache — Pre-computed signed pointers indexed by address byte, enabling real-time hook callbacks without cryptographic latency
- RWTransfer — A mechanism to transfer kernel read/write capabilities between processes using guarded file descriptors and Mach port manipulation
- callFunc — A remote function execution framework that hijacks thread state through Mach exception messages
- 21 supported device models spanning iPhone XS through iPhone 14 Pro Max, organized into 5 device classes
Background: the security features Predator must defeat
Pointer Authentication Codes (PAC)
Starting with the A12 chip (iPhone XS, 2018), Apple introduced PAC — a hardware feature that adds cryptographic signatures to code pointers. Before the processor follows function pointer or return address, it verifies the signature. If an attacker corrupts a pointer, the signature check fails and the processor raises an exception.
Kernel Address Space Layout Randomization (KASLR)
iOS randomizes the kernel base address at each boot (KASLR), meaning all kernel code and static data structures shift by an unpredictable offset. Even if an attacker has a kernel vulnerability, they must first determine this slide to locate the structures they want to manipulate. This requires a reliable kernel memory read primitive — exactly what FDGuardNeonRW provides.
Finding 1: FDGuardNeonRW — kernel memory access through vector registers
Decoding the name
The class name FDGuardNeonRW encodes its entire technique:

This is the core primitive that powers everything else in Predator. Every hook, every process injection, every PAC bypass ultimately depends on FDGuardNeonRW’s ability to read and write arbitrary kernel memory.
The NEON data channel
ARM NEON is a set of 128-bit vector registers (V0–V31) normally used for SIMD operations — parallel math on multiple values simultaneously. They are part of the thread state that the kernel saves and restores during context switches.
Predator exploits this using a well-established technique: the Mach thread_get_state and thread_set_state APIs allow reading and writing of a thread's full register state, including NEON registers, from another thread with appropriate port rights. This thread-state manipulation approach has been used in iOS exploit chains since at least 2017. Predator's innovation is channeling kernel data through the NEON register bank specifically — its 32 × 128-bit vector registers yield 528 bytes per thread_get_state call (including FPSR, FPCR and alignment padding), compared to the 272 bytes available through the general-purpose register state.
This channel depends on a kernel-side component established by the initial exploit — the NEON registers serve as the transport, but the actual kernel memory reads and writes are performed by code running at kernel privilege. The full details of this kernel-side payload are outside the scope of this post.
Figure 1: FDGuardNeonRW read and write primitives using NEON registers as a high-bandwidth kernel data channel
Read primitive (528 bytes per read)
The read operation relies on a kernel code path installed by the initial exploit stage. This code path loads data from a controlled kernel address into NEON registers, then hits a trap instruction. The target thread is resumed, executes this code path, and triggers the trap. Predator’s exception handler receives a Mach exception message (Figure 3; identified by msgh_id 2406 / 0x966) containing the NEON state with kernel data. Up to 10 retries handle timing races. Each read retrieves 528 bytes.
Write primitive (poll-confirmed)
The write operation reverses the channel. Predator suspends the target thread, reads the current VFP/NEON state as a baseline, modifies it with the target address and data at a device-specific offset, then sends an exception reply with the modified state. The kernel restores the modified NEON state into the thread's saved context. When the thread resumes, the exploit's kernel code path reads the values from the NEON registers and writes them to the target kernel address. Predator polls for up to 3 seconds, comparing the NEON state readback against the sent data to confirm the write succeeded.
Why NEON Registers?
NEON state is:
- Large capacity — 512+ bytes per operation
- Kernel-managed — part of normal thread state handling
- Exception-visible — included in Mach exception messages
- Bidirectional — same mechanism for reads and writes.
Figure 2: IDA graph view of the NEON write primitive – thread_suspend, exception reply with NDR_record, doSend, thread_resume, and the 2-second polling loop

Figure 3: Decompiled NEON read primitive — the retry loop (v11 = 10), mach_msg receive, validation of msgh_id == 2406 and VFP state count == 65, and final thread_suspend
Finding 2: hunting for PAC gadgets in JavaScriptCore
The problem
To install hooks in system processes, Predator needs to redirect function execution — which means modifying code pointers. On PAC-enabled devices (iPhone XS and later), every code pointer carries a cryptographic signature. Predator must forge valid signatures for its redirected pointers.
The solution: borrowing Apple’s own code
Rather than bringing its own signing implementation, Predator searches Apple’s JavaScriptCore framework for an existing code sequence that performs PAC signing with controllable inputs. The target function is JSC::JSArrayBuffer::isShared() — present on every iOS device as part of Safari’s JavaScript engine.
Figure 4: PAC bypass via JSC gadget hunting and 256-entry pre-computed signing cache
The 20-byte gadget
Predator searches within 0x1000 bytes of the isShared symbol using memmem() for this exact 20-byte pattern:
The PACIA X16, X17 instruction is the key: it signs the pointer in X16 using X17 as the context/discriminator, with the hardware PAC key. By controlling X16 and X17, Predator can forge signatures for arbitrary pointers.
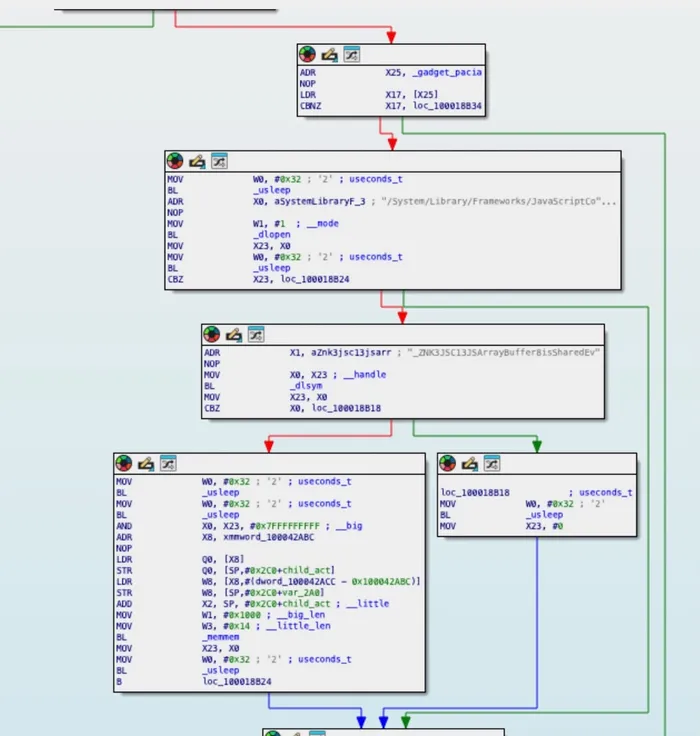
Figure 5: IDA graph view of remotePACIA — the gadget hunting flow: check gadget_pacia cache → dlopen(JavaScriptCore) → dlsym(isShared) → memmem(pattern, 0x14)
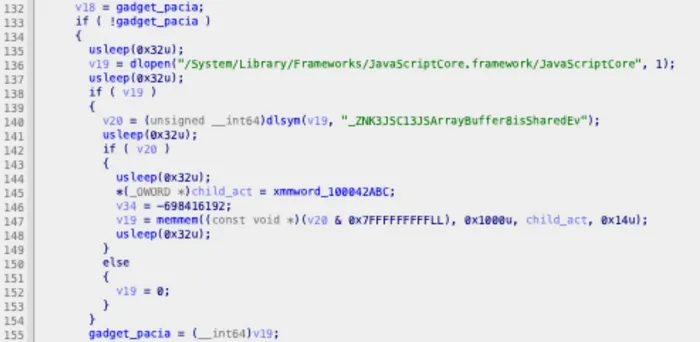
Figure 6: Decompiled gadget search — dlopen, dlsym for _ZNK3JSC13JSArrayBuffer8isSharedEv, pattern match via memmem with the 20-byte PACIA gadget pattern stored at xmmword_100042ABC

Figure 7: Hex view at 0x100042ABC showing the 20-byte gadget pattern: 30 02 C1 DA (PACIA X16, X17) highlighted in the binary’s constant data section
Finding 3: the 256-entry PAC signing cache
Each call to remotePACIA involves creating a thread, setting up exception ports, modifying kernel thread state, executing the gadget and receiving the result. This takes milliseconds — far too slow for hook callbacks that must complete in microseconds.
Pre-computed signing table
Predator builds a cache of 256 pre-signed pointers at initialization, covering every possible top-byte value of an address. When a hook fires, the correctly signed pointer can be looked up instantly.
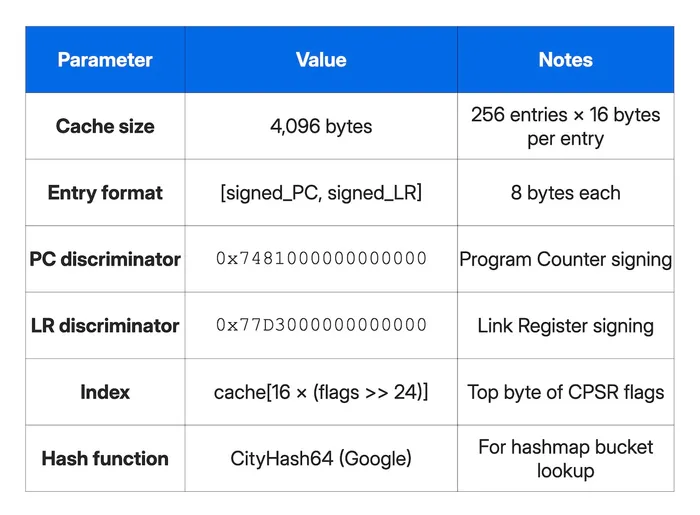
Using separate discriminators for PC and LR means a signed return address cannot be substituted for a signed jump target — a defense-in-depth measure from Apple that Predator must account for. The expensive remotePACIA calls (256 × 2 = 512 calls per cache) happen once per unique function target. All subsequent hook callbacks are instant cache lookups.
Finding 4: callFunc — remote function execution
callFunc is Predator’s primary mechanism for executing arbitrary functions in remote processes. It combines the PAC cache, Mach exceptions and thread state manipulation into a single callable primitive that accepts a function pointer and up to 6 arguments (x0–x5).
The mechanism
A “trojan thread” (Predator’s internal term) sits in the remote process at a breakpoint, generating continuous Mach exceptions. callFunc receives the exception, fills argument registers, and looks up the correctly signed PC and LR from the PAC cache. The exception reply contains the modified thread state — when the kernel delivers the reply, the trojan thread resumes execution at the target function with the specified arguments.
The “poison LR” return address points back to another breakpoint, so when the function returns, a new exception is generated and Predator regains control. This creates an infinitely reusable remote procedure call mechanism.
Source reference: The function at 0x10000B028 logs its file origin as “TaskROPDevOff.h” — confirming this is a ROP-based technique designed for devices without Developer Mode enabled.

Figure 8: Decompiled callFunc — PAC cache miss triggers signState to build 256-entry cache (LABEL_33), while cache hit (LABEL_38) performs instant lookup via getFlags >> 24, then setPC/setLR with signed pointers before ExceptionMessage::Send
Finding 5: RWTransfer — sharing kernel primitives across processes
Predator’s architecture splits functionality across multiple processes: a “watcher” manages the lifecycle, while “helper” processes perform actual surveillance. The watcher obtains kernel R/W through the initial exploit, but helpers also need it. RWTransfer solves this.
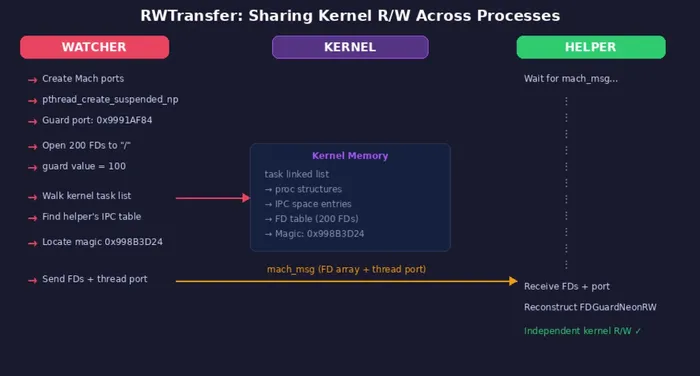
Figure 9: RWTransfer protocol for sharing kernel R/W capabilities between processes

The watcher walks kernel-linked lists (with offsets specific to device class) to find the helper’s task structure, then its IPC space, then individual port entries. This is one of the most complex components in Predator — involving simultaneous manipulation of Mach ports, file descriptors, kernel linked lists and thread states.
Finding 6: remote Objective-C method resolution
When Predator needs to hook an Objective-C method in a remote process, it can’t always rely on local runtime queries. While methods implemented within the dyld shared cache are mapped at identical addresses across all processes on the same boot, methods in application-specific binaries are subject to per-process ASLR slides. Predator therefore executes the full Objective-C runtime resolution chain remotely using callFunc, ensuring correct results regardless of where the target method is implemented:

Each callFunc invocation goes through the full Mach exception → PAC cache → thread state manipulation pipeline. Performing all four steps remotely guarantees correct resolution even for methods outside the shared cache, where the local and remote addresses would differ due to independent ASLR slides.
Finding 7: device support matrix — 21 models in 5 classes
Kernel structure layouts vary between iPhone models due to differences in SoC generation, security features and iOS kernel builds. Predator maintains per-device-class configurations with precise kernel offsets.
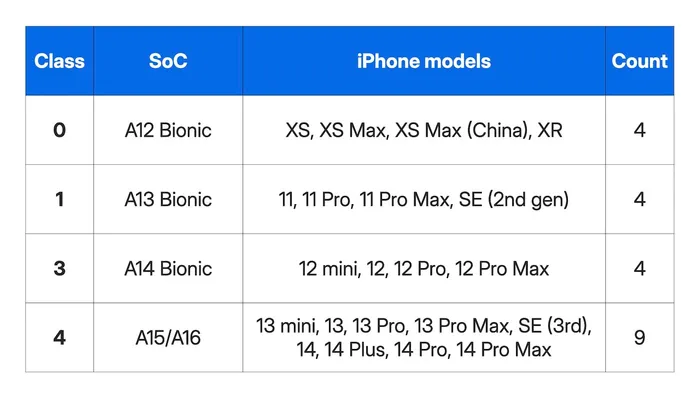
Note: Device class 2 is not used in this sample — likely reserved for a hardware revision or merged with another class. Unsupported devices cause the function to return 5, aborting execution rather than risking a kernel panic. Total: 21 iPhone models spanning 2018–2022 hardware.
Decoding the XOR comparisons
The decompiled code (Figure 10) appears to contain opaque hexadecimal constants, but these are simply XOR-encoded ASCII strings. The function calls uname() to retrieve the device’s machine identifier (e.g, “iPhone15,3”), then performs XOR comparisons — if the result equals zero, the device matches. The encoding is straightforward: 0x3531 is ASCII “15” and 0x332C is ASCII “,3”, both in little-endian byte order. Each condition in the decompiled output maps directly to a specific iPhone model identifier.
For example, the first condition in the return 4 block:
qword_1000491A0 ^ 0x3531656E6F685069 → "iPhoneXX" portion
(char *)&qword_1000491A0 + 3) ^ 0x332C3531656E6F → "oneXX,Y" portion
When both XOR results are zero, the device string matches "iPhone15,3" — the iPhone 14 Pro Max.
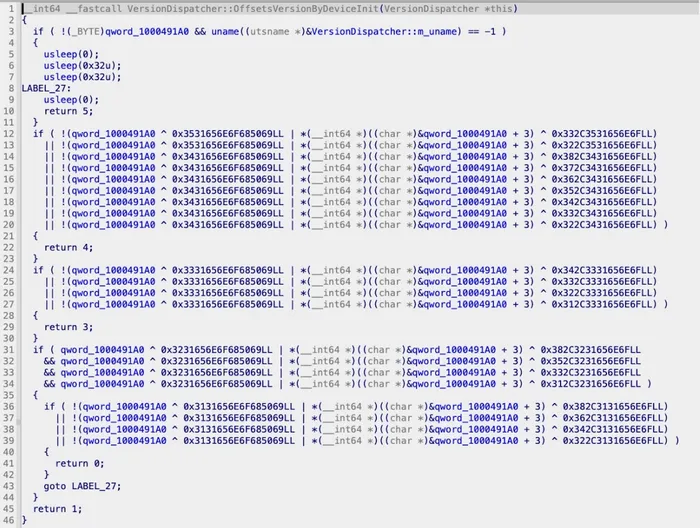
Figure 10: Decompiled VersionDispatcher::OffsetsVersionByDeviceInit — device identification via uname() with XOR-based string comparison returning device classes 0–4, returning 5 for unsupported models to abort safely
The complete attack chain
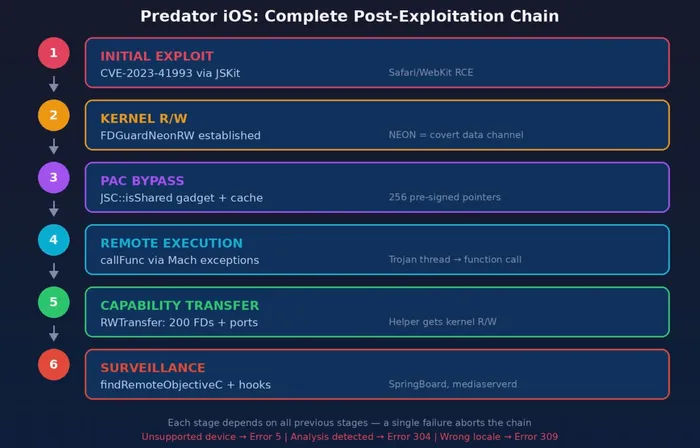
Figure 11: Complete post-exploitation chain from initial exploit to active surveillance
Each stage depends on all previous stages — a single failure at any point aborts the chain. Combined with the error code system documented in our first post, this gives Predator operators precise diagnostic information about which stage failed and why.
Conclusion
FDGuardNeonRW demonstrates that ARM NEON vector registers, designed for parallel computation, can be repurposed as a covert kernel memory access channel. The 528-byte read and poll-confirmed write primitives are reliable enough to support Predator’s entire post-exploitation framework.
The PAC bypass illustrates that hardware security features, while raising the bar significantly, can be circumvented when an attacker has kernel read/write access. By hunting for gadgets in Apple’s own frameworks and pre-computing a signing cache, Predator defeats pointer authentication with negligible runtime overhead.
The capability transfer mechanism reveals the engineering sophistication of commercial spyware. Transferring kernel R/W access between processes — involving simultaneous manipulation of Mach ports, file descriptors, kernel linked lists and thread states — reflects sustained, professional engineering investment.
These findings underscore a sobering reality: commercial spyware vendors are investing heavily in post-exploitation engineering, not just initial vulnerability discovery. Defending against these capabilities requires security measures that operate below the level that these tools compromise — hardware-rooted attestation, sealed kernel memory and out-of-band monitoring that doesn’t rely on the integrity of the device’s own software stack.
References
1. Jamf Threat Labs, “Predator’s Kill Switch: Undocumented Anti-Analysis Techniques in iOS Spyware,” January 2026
2. Jamf Threat Labs, “How Predator Spyware Defeats iOS Recording Indicators,” February 2026
3. Google Threat Intelligence Group, “Sanctioned but Still Spying: Intellexa’s Prolific Zero-Day Exploits Continue,” December 2025
4. Apple, Apple Platform Security Guide
Read the latest research from Jamf Threat Labs